
Bem, HA (High Availability – Alta disponibilidade) é um assunto bem procurado por administradores de infraestrutura, pois muitos o querem em seu ambiente (lê-se: seu pescoço), afim de deixá-lo o mais seguro e resiliente possível. Aliado a isto, o fato de esse recurso ser completamente open source (aêêêêê) no XenServer 6.5, contribui bastante para sua adoção.
A facilidade de configuração de HA coloca este recurso na lista dos top 10 mais utilizados no XenServer.
Mas, em quê consiste o HA? Simples, este sistema tenta proteger seu ambiente (suas Vms) em caso de falhas físicas ou lógicas no host xen.
E o que ele faz para tentar garantir isso? Ele tentará migrar as VMs do host xen falhado para algum host vivo (e de bem com a vida). Para isso, o HA faz uso do recurso XenMotion (falo sobre XenMotion aqui).
Explicando o HA de forma mais completa:
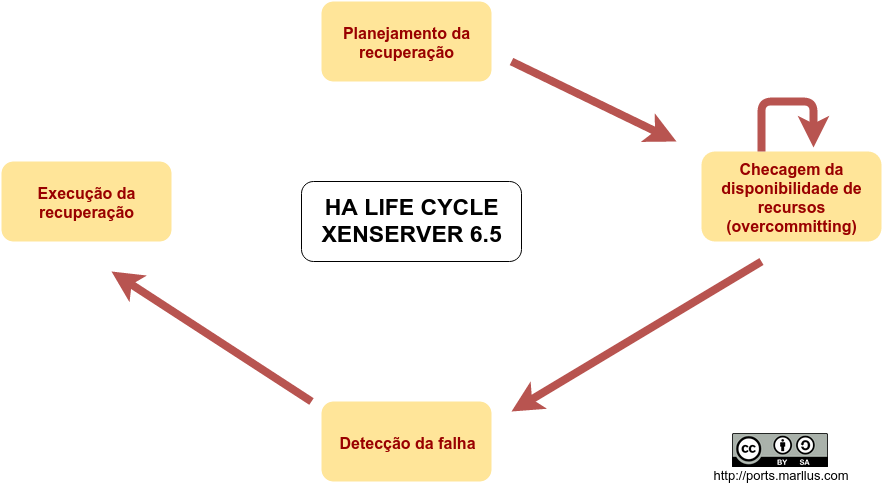
Os alicerces para o funcionamento do HA em um pool de recursos são: Planejamento da disponibilidade dos recursos, detecção da falha e execução da recuperação.
Planejamento da disponibilidade dos recursos:
Neste etapa, o HA irá planejar qual a tolerância de falha nos servidores (quantos servidores podem falhar) dentro do pool. Basicamente, baseado em quantas Vms você quer proteger dentro de cada host, o próprio HA emitirá um aviso informando qual o limite de servidores que podem falhar no pool para que essas Vms sejam ligadas em outros servidores ativos.
Portanto, se você quiser ter resiliência total do seu ambiente, deixe sempre uma reserva de recurso (RAM e CPU) em cada host. Essa reserva será utilizada para alocar Vms de hosts que podem vir a falhar. Claro, o tamanho desta reserva vai depender de quantos hosts e quanto de recurso (RAM e CPU) você terá e quantas Vms você vai querer “salvar”.
O HA sempre calculará, automaticamente, a quantidade de recursos disponíveis no pool para lhe dizer qual tolerância de falhas você tem naquele momento.
Detecção da falha:
Quando você for configurar o HA em um pool, o Xenserver vai pedir para escolher um SR onde ele irá gravar o keep alive dos servidores. Este será um SR compartilhado (no pool) chamado Heartbeat SR (que armazena o “batimento cardíaco” dos servidores – 356Mb tamanho). Ele nada mais armazena do que informações de status (vida [response] ou morte [timeout]) de cada servidor no pool. Em um intervalo de tempo, cada servidor fornece a informação que está vivo para este SR (keep alive). Se esta informação não chegar, o HA reconhecerá que o servidor morreu e tentará seguir o plano de recuperação das Vms (de acordo com o que você planejou).
Pode acontecer de um host perder as configurações de rede, ou um bug no toolstack, ou um administrador descuidado retirar ou alterar o ip de gerência do host para uma faixa desconhecida. Nestes casos, a comunicação do host para o storage não foi perdida (ou seja, as Vms continuarão rodando normalmente), porém o host xen ficará inacessível. Para nossa alegria, o HA consegue detectar que houve falha na rede (sim, ele também checa de tempos em tempos a rede do host). Quando ocorre isso, entra em cena um recurso chamado host fencing, que vai desligar o host, e tentar recuperar as Vms protegidas associadas a ele, migrando-as para outro host com recurso disponível.
Execução da recuperação:
Acontece o que expliquei em tópicos anteriores. Se o host deixar de mandar um keep-alive para o storage ou se a rede de gerência do host for perdida (por algum motivo) iniciará o processo de recuperação das Vms, realizado pelo sistema de HA do XenServer. Nestes dois casos, o servidor estará indisponível e as Vms serão migradas para outro host disponível no pool de recursos.
Resumindo (mais do que foi resumido):
Na criação do HA, você seleciona quais Vms vão ser reiniciadas em caso de falhas (indicando qual a ordem de inicialização). Dinamicamente, o HA vai mostrando se ele tem condições de recuperar todas as Vms. É perguntado também qual a tolerância que você quer para falhas em servidores (configured failed capacity) e, automaticamente, o Xenserver vai te dizer se é possível ele garantir essa recuperação (current failed capacity).
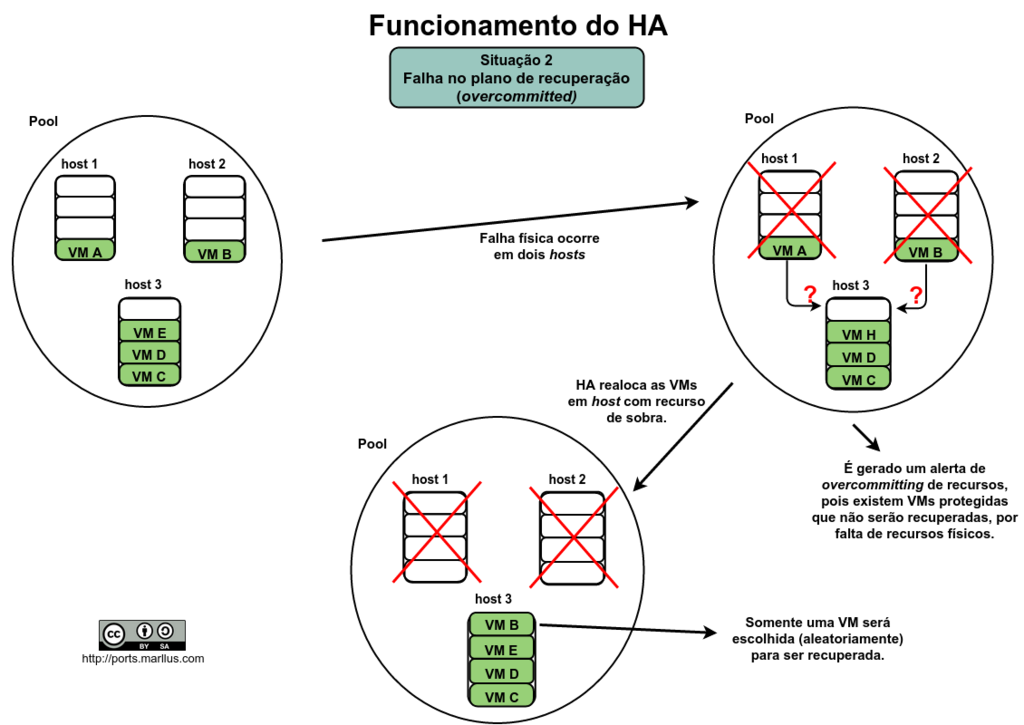
Lembrando que o valor do “current failed capacity” vai alterando dinamicamente de acordo com o provisionamento ou alteração de novas Vms no pool, pois, ao longo do tempo os recursos de RAM e CPU entram em escassez, podendo chegar no ponto em que os recursos de “sobra” nos hosts não sejam suficientes para garantir o plano de recuperação configurado pelo administrador (esse ponto é conhecido como overcomitted). Não se preocupe, o Xenserver enviará alertas automaticamente pelo Xencenter ou por e-mail (se configurado) quando o recurso físico disponível não suportar recuperar todas as Vms protegidas pelo HA. Então, fique atento!
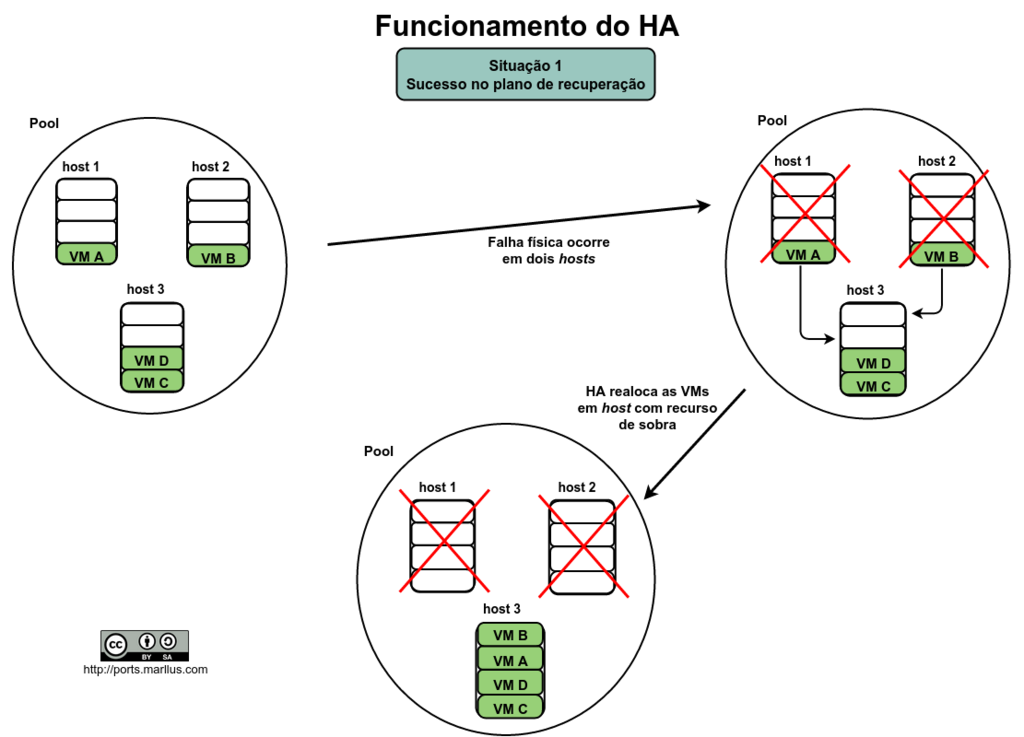
Resumindo (com imagens) com duas situações, uma com sucesso e outra sem sucesso no plano de recuperação (por causa de overcommitting):
Ciclo de vida do HA no Xenserver:
Requisitos e recomendações:
-
– Um pool de recursos, logicamente;
-
– Recomenda-se pelo menos 3 hosts nesse pool;
– Um SR compartilhado, sendo este do tipo NFS, iSCSI ou FC de pelo menos 356MB ou superior. Destes 356MB serão: 4MB para dados do heartbeating e 256MB para metadados do membro master do pool, para os casos onde ele falhará.
A citrix recomenda que você utilize um SR dedicado para conter estes dados.
– IP estático para todos os hosts no pool;
Se o endereço de IP de um host mudar, provavelmente o HA considerará que a sua rede falhou e irá ativar o host fencing. Para remediar isto, basta desabilitar o HA (comando # host-emergency-ha-disable) e resetar o membro master do pool (comando # pool-emergency-reset-master) e só então reabilitar o HA.
– vDisks (discos virtuais) de VMs deverão estar em storages compartilhados;
– Vms não devem ter conexão ativas para unidades de DVD local do host xen;
– Vms devem ter interfaces de rede virtuais disponíveis em todo o pool;
Algumas considerações:
– Update/Upgrade de Xenserver: Antes de qualquer procedimento deste tipo, desabilite o HA, pois, muito provavelmente seu servidor precisará ter seu XAPI ou kernel reinicializado. Você não quer que o HA entenda isso como uma falha, né?
– Vms configuradas no plano de HA pela opção de best-effort não estão protegidas através do plano de recuperação de Vms do HA. Como o próprio nome já sugere (melhor esforço), o sistema do HA tentará alocar uma VM em um servidor onde haja espaço em recursos. Por isso, as VM com prioridades de reinicialização 0, 1, 2 e 3 são as únicas que estarão no plano de recuperação do HA. Então, fique de olho no que é serviço crítico em seu ambiente.
– No planejamento de reinicialização, sempre é bom estabelecer tanto a prioridade quanto o delay das reinicializações. A primeira serve para definir quem irá rebootar primeiro (DHCP, AD, SAMBA, DNS, por exemplo) e o atraso entre estes reboots. Por exemplo, você não vai querer que o serviço de DHCP de sua rede entre depois de um serviço SAMBA, ou que uma aplicação que usa um compartilhamento do SAMBA ligue após o próprio SAMBA, não é? Fora isso, ainda tem o problema da “chuva de boots” que consiste no overhead do Dom0 para gerenciar o boot de muitas Vms ligando de uma vez. A “chuva de boots” pode comprometer o desempenho de seu ambiente de virtualização.
– Considere utilizar multipathing na comunicação para seu(s) storages e configurar bond nas interfaces de rede de gerência de cada host no pool protegido por HA. Ter duplicação de caminhos para rede e armazenamento melhora, consideravelmente, a capacidade que o(s) host(s) têm de ficarem ativos em caso de falha em uma NIC (placa de rede). Isso reduz a probabilidade de ativação do HA (pois é isso que queremos, certo?).
Bem, para finalizar, deixo aqui os passos (através de documentação oficial) necessários para habilitar o HA em um pool de Xenservers.
http://support.citrix.com/article/CTX121708
Espero que tenha gostado do tutorial!
Até mais!
Referências:
http://support.citrix.com/article/CTX121708

Este trabalho de Marllus, está licenciado com uma Licença Creative Commons – Atribuição-CompartilhaIgual 4.0 Internacional.